Quickstart
Before you start, make sure that you have access to Snowflake account and prepare the following information:
Snowflake Username
Snowflake Password
Snowflake Account Name
Snowflake Warehouse Name
Snowflake Database Name
Snowflake Schema Name
Snowflake password (you will store it locally in an environment variable)
You will also need:
Python 3.8 (must-have ⚠️ - this is enforced by the snowflake-snowpark-python package. Refer to Snowflake documentation for more details.
A tool to manage Python virtual environments (e.g. venv, conda, virtualenv). Anaconda is recommended by Snowflake.
Prepare new virtual environment with Python == 3.8.
Install the plugin
pip install "kedro-snowflake>=0.1.2"
Create new project from our starter
kedro new --starter=snowflights --checkout=0.1.2
Project Name
============
Please enter a human readable name for your new project.
Spaces, hyphens, and underscores are allowed.
[Snowflights]:
Snowflake Account
=================
Please enter the name of your Snowflake account.
This is the part of the URL before .snowflakecomputing.com
[]: abc-123
Snowflake User
==============
Please enter the name of your Snowflake user.
[]: user2137
Snowflake Warehouse
===================
Please enter the name of your Snowflake warehouse.
[]: compute-wh
Snowflake Database
==================
Please enter the name of your Snowflake database.
[DEMO]:
Snowflake Schema
================
Please enter the name of your Snowflake schema.
[DEMO]:
Snowflake Password Environment Variable
=======================================
Please enter the name of the environment variable that contains your Snowflake password.
Alternatively, you can re-configure the plugin later to use Kedro's credentials.yml
[SNOWFLAKE_PASSWORD]:
Pipeline Name Used As A Snowflake Task Prefix
=============================================
[default]:
Enable Mlflow Integration (See Documentation For The Configuration Instructions)
================================================================================
[False]:
The project name 'Snowflights' has been applied to:
- The project title in /tmp/snowflights/README.md
- The folder created for your project in /tmp/snowflights
- The project's python package in /tmp/snowflights/src/snowflights
Pipeline name parameter is here to allow you run many pipelines in the same database in snowflake and avoid conflicts between them. For demo it’s fine to leave it as default.
Leave the mlflow integration disabled for now. More instructions on how to get the integration to work will available later in a blog post.
The
Snowflake Password Environment Variableis the name of the environment variable that contains your Snowflake password. Make sure to set in in your current terminal session. Alternatively, you can re-configure the plugin later to use Kedro’s credentials.yml. For example (using env var):
export SNOWFLAKE_PASSWORD="super_secret!"
Go to the project’s directory:
cd snowflightsInstall the requirements
pip install -r src/requirements.txt
Launch Kedro pipeline in Snowflake
kedro snowflake run --wait-for-completion
After launching the command, you will see auto-refreshing CLI interface, showing the progress of the tasks execution.
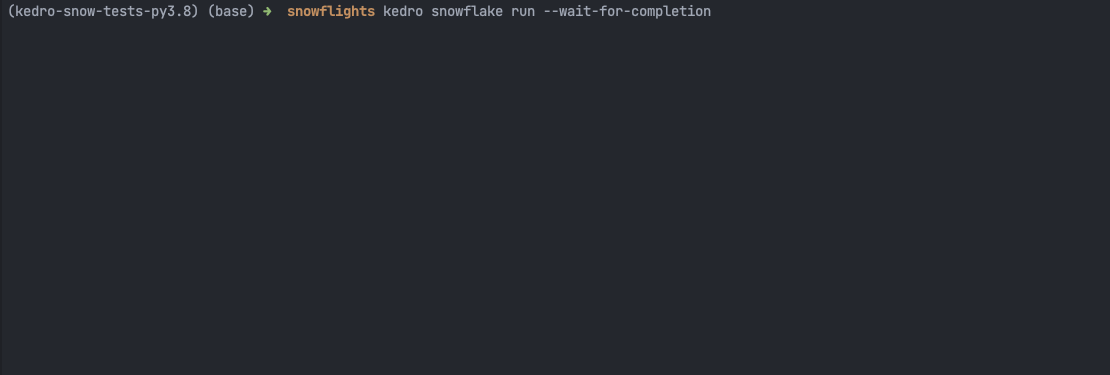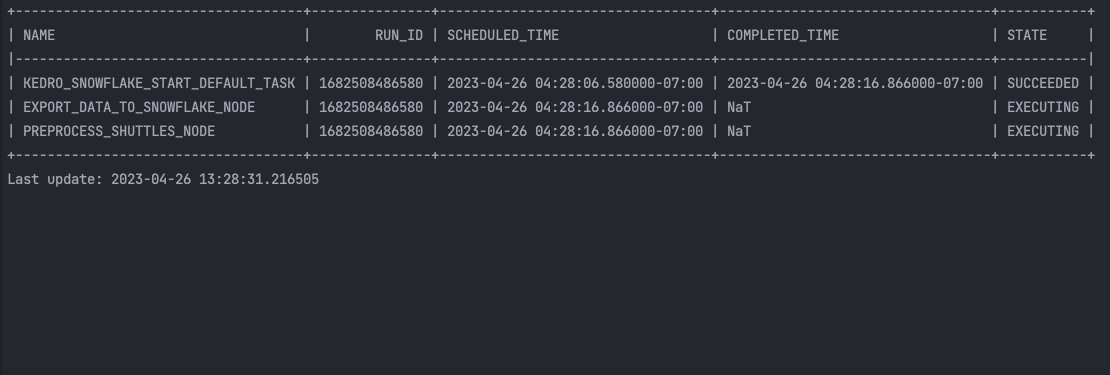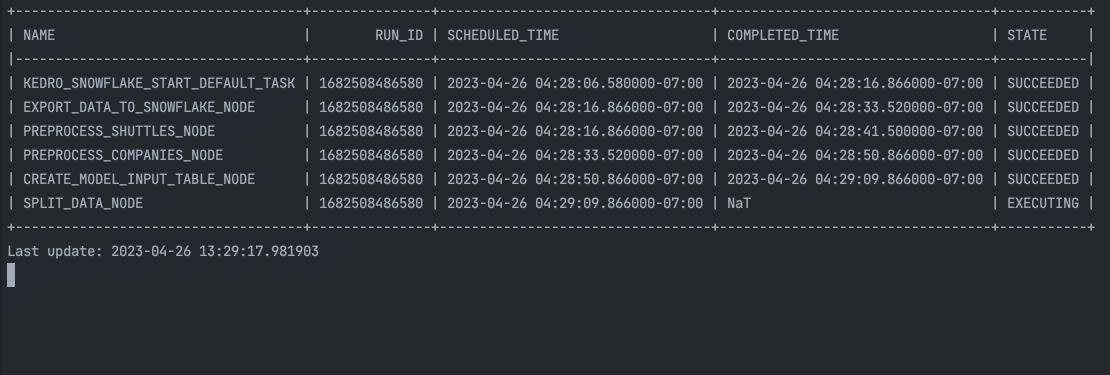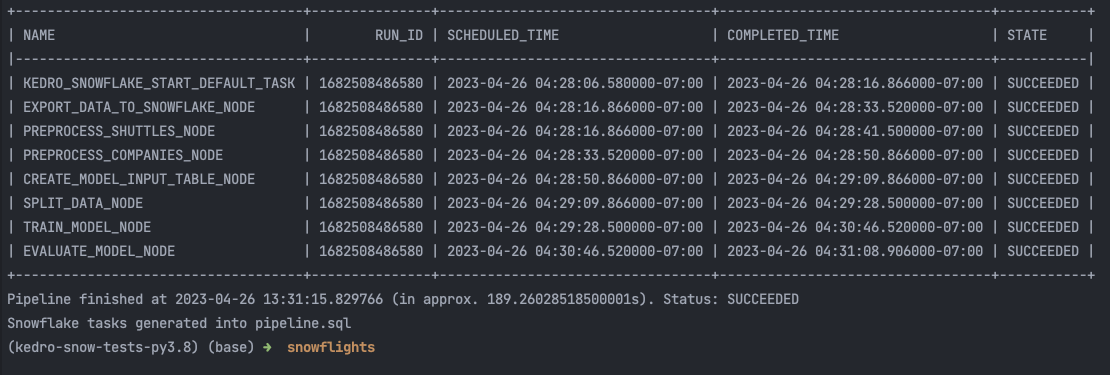
In Snowpark, you can also see the history of the tasks execution:
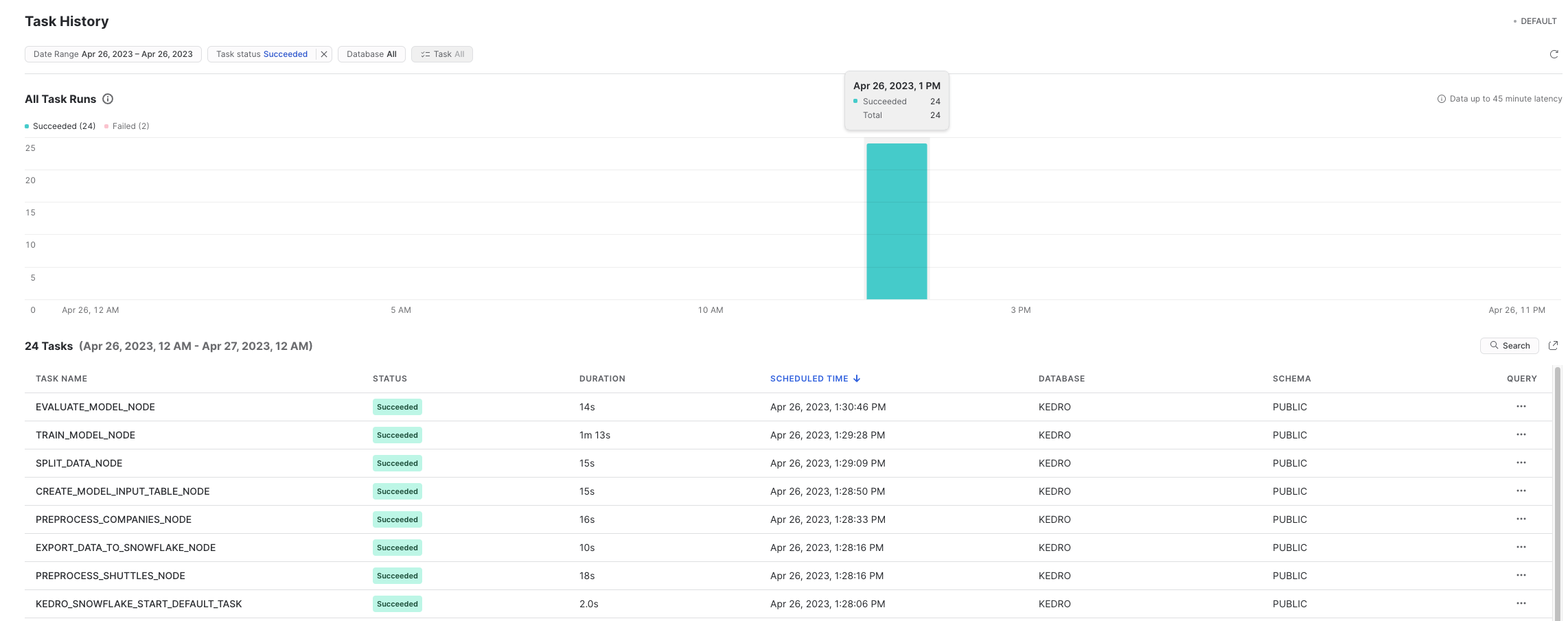
Advanced configuration
This plugin uses *snowflake.yml configuration file in standard Kedro’s config directory to handle all its configuration. Follow the comments in the example config, to understand the meaning of each field and modify them as you see fit.
snowflake:
connection:
# Either credentials name (Reference to a key in credentials.yml as in standard Kedro)
# or leave
# credentials: ~
# and specify rest of the fields
credentials: snowflake
# account: "abc-123"
# database: "KEDRO"
# Name of the environment variable to take the Snowflake password from
# password_from_env: "SNOWFLAKE_PASSWORD"
# role: ~
# schema: "PUBLIC"
# user: "user2137"
# warehouse: "DEFAULT"
runtime:
# Default schedule for Kedro tasks
schedule: "11520 minute"
# Optional suffix for all kedro stored procedures
stored_procedure_name_suffix: ""
# Names of the stages
# `stage` is for stored procedures etc.
# `temporary_stage` is for temporary data serialization
stage: "@KEDRO_SNOWFLAKE_STAGE"
temporary_stage: '@KEDRO_SNOWFLAKE_TEMP_DATA_STAGE'
# List of Python packages and imports to be used by the project
# We recommend that this list will be add-only, and not modified
# as it may break the project once deployed to Snowflake.
# Modify at your own risk!
dependencies:
# imports will be taken from local environment and will get uploaded to Snowflake
imports:
- kedro
- kedro_datasets
- kedro_snowflake
- omegaconf
- antlr4
- dynaconf
- anyconfig
# packages use official Snowflake's Conda Channel
# https://repo.anaconda.com/pkgs/snowflake/
packages:
- snowflake-snowpark-python
- cachetools
- pluggy
- PyYAML==6.0
- jmespath
- click
- importlib_resources
- toml
- rich
- pathlib
- fsspec
- scikit-learn
- pandas
- zstandard
- more-itertools
- openpyxl
- backoff
# Optionally provide mapping for user-friendly pipeline names
pipeline_name_mapping:
__default__: default
Snowflake datasets
This plugin integrates with Kedro’s datasets and provides additional set of datasets for Snowflake.
The catalog.yml in our official Snowflights starter shows example usage of each of them:
companies:
type: kedro_datasets.snowflake.SnowparkTableDataSet
table_name: companies
database: kedro
schema: PUBLIC
credentials: snowflake
reviews:
type: pandas.CSVDataSet
filepath: data/01_raw/reviews.csv
shuttles:
type: pandas.ExcelDataSet
filepath: data/01_raw/shuttles.xlsx
load_args:
engine: openpyxl # Use modern Excel engine, it is the default since Kedro 0.18.0
preprocessed_shuttles:
type: kedro_snowflake.datasets.native.SnowflakeStageFileDataSet
stage: "@KEDRO_SNOWFLAKE_TEMP_DATA_STAGE"
filepath: data/02_intermediate/preprocessed_shuttles.csv
credentials: snowflake
dataset:
type: pandas.CSVDataSet